One of the most important metrics that we use to measure the size of a Visual Basic 6.0 code base to be migrated is called Effective Lines of Code. This measurement represents all those lines that will require a certain amount of migration effort and in the case of Visual Basic 6.0 to .NET migrations, it includes the following:
- Visual lines of code: this includes all the code that is automatically generated by the VB6 forms designer. This code belongs to .frm and .ctl files and is not visible to the programmer (if you open a .frm or .ctl file in a text editor such as Notepad, you will see this visual code at the beginning of the file). The reason why we include this as part of the code base to be migrated is that VB6 user interface also represents a manual migration effort, together with VB6 source code.
Naturally, the Effective Lines of Code metric does not include blank or comment lines since they do not imply any migration effort.
Working days, or business days, are usually said to be 8 hours long. On an average day, you may get to work at 8:30 am and leave by 5:30 pm, having 1 hour for lunch (although this differs from one culture to another, just ask someone from Mexico and you’ll see what I mean!).
Anyway, people usually spend 8 hours at work everyday. However, this doesn’t mean that people are 100% productive in the tasks they’ve been assigned to during those 8 hours. During a normal working day, normal people also check email, make phone calls, talk to their coworkers and do other things that are not necessarily related to the tasks they are working on. As a result, working days are pretty much like soccer games: while a soccer game is said to last 90 minutes, the effective playing time is usually much less than that. Likewise, the effective working time in an 8-hours business day is lower than 8 hours.
The amount of effective hours may vary from an organization to another and from an individual to another. Organizations that keep good project metrics may have a better idea of the average number of effective working hours per day. The important thing to keep in mind here is that even when a team member may be assigned full-time to a task, it cannot be assumed that he or she will devote 8 hours per day to that task. Therefore, it makes sense to think that a task that has an estimated effort of 16 person-hours will take a little more than 2 days to complete with one resource.
Let us gently start meeting PaXQuAL, a prototype language that we are shaping out and adjusting
for the emergent purpose of symbolically expressing analysis and transformation
simple tasks around Web Pages, all this circumscribed in the
context of refactoring, as we have
been done in previous posts.
And as we also have already done days before, sometimes we
just want to digress a little bit from practical and realistic issues, just to
expose some theoretical ideas we find somehow interesting (and probably nobody
else). I just can promise that no Greek letter will be used, at all (in part
because that Font is not allowed by the publishing tool, I confess).
Anybody (if any) still reading this post is allowed to right
away express the nowadays classical: “Yet another language? How many do we count
up by now?” Claim is justified because everybody knows that every problem in
Computer Science is solved proposing a (the) new one. Now it is my turn, why
not. It’s a free world. For the interested reader a technical paper will be hopefully
available with further details at this site, soon.
Actually PaXQuAL (Path
based Transformation and Querying Attribute Language is his real name; is pronounced Pascual) is not that new and different from many other languages,
developed for real researchers at the academia and industry. We wanted to imagine
a language for querying and transforming structured data (eg. XML, HTML) and from that sort we have many available as we know. What
new material can be proposed at this field for someone like us? Actually,
what we really want is to operationally relate CSS with some special sort of theoretical weird artifact we had
been exploring some years ago that we may dare to call Object-Oriented Rewrite Systems or Term-rewriting Systems (TRS) with extra variables and state
(as a result of some work developed by and joint with actual researchers some
years ago). Considering TRS in this case
natural because CSS is indeed a kind of them and that field has a rich offering
of tools for useful automated reasoning. And we can find them useful here, we
guess.
The question that pushed us back to the old days is: given an
interesting, so simple and practical language, like CSS is, what kind of object-oriented
rewriting logic can be used to describe its operational semantics. You may not
believe it but this is a very important issue if we are interested in reasoning
about CSS and HTML for refactoring purposes among others. And we are, don’t we?
CSS is rule-based, includes path-based pattern matching and
is feature (semantically attributed) equipped, which all together yields a nice
combination. CSS can be considered “destructive” because it allows adding or
changing (styling) only attributes of tags where remaining “proper content”
does not result destructively rewritten. It is not generative, by such a reason
(in contrast to XSLT and XQUERY). And that leads to an
interesting paradigm. For instance, following is a typical simple CSS rule for
setting some properties of every tag of the kind body.
body {
font-family:
Arial, Helvetica, sans-serif;
background-color:
#423f43;
text-align:
center;
}
Of course more explicit rules like this one can be declared
but further, an inheritance (cascading) mechanism implicitly allows that
attributes may be pushed down or synthesized as we know from attribute grammars.
That all is nice but we feel we had to be original and want
to propose the crazy idea of using something similar to CSS for purposes beyond
setting style attributes, for instance for expressing classification rules
allowing to recognize patterns like
the ones we explained in previous posts. For instance, that a table is actually
a sort of layout object, navigation bar or a menu, among others. Hence, we
would have a human-readable, querying and transformation language for Web
Pages, a sort of CSS superset (keeping CSS as a metaphor what we think might be
a good idea):
Let us by now just expose some examples (where we advert
concrete syntax in PaXQuAaL is not yet definitive). For instance, we may want
to eliminate the bgcolor attribute of any table having it because is
considered deprecated in XHTML. We use symbol “-:“ for denoting execution of
the query/transformation as in Prolog.
:- table[bgcolor]{bgcolor:null;}
We may want to add a special semantic attribute to every
table directly hanging from a body, indicating it may be a surface object for
some latter processing. We first must statically declarate a kind of table, “sTable”,
accepting a surface attribute because we are attempting to use static typing as
much as possible (“Yes I am still a typeoholic”)
@:- sTable::table[surface:boolean;]{surface:false}
Symbol “@:-” is like “:-” but operating at the
terminological level. And then we have the rule for classifying any table
instance hanging from the body tag, directly:
:- body sTable{surface:true;}
Many more "interesting" issues and features still need to be introduced;
we will do that in forthcoming post. Hence, stay tuned.
I like Linux and consider it as a very interesting OS alternative
However sometimes there are simple things that I just do not know how to do.
Windows is still everywhere and specially getting thing
from a Windows to a LINUX box can be tricky.
For example recently I had to restore a database
from a Windows DB2 to a Linux DB2 so I had the backup and needed to
eove it to the linux box.
So use smbclient!
But how.
Ok.
to connect to a windows share do something like this:
smbclient -user domain/username //machine/sharename
this thing will ask for your password and now you are connected.
Smbclient is just like an ftp.
But how do you copy a directory
I found these instructions in the internet:
smb: > tarmode
smb: > lcd /tmp
smb: > recurse
smb: > prompt
smb: > mget your_directory/
as simple as that.
So hope that helps
For some reason, several people have told me that they are not getting the link to download the Virtual Machine Additions for Linux on Microsoft Connect anymore. If that happens to you, try the direct link: https://connect.microsoft.com/content/content.aspx?ContentID=1475&SiteID=154 . You will still need to enter your Passport Live ID in order to access the Connect website, but that link should take you directly to the Linux Additions page.
So what is the story with Vista? You've read the hype, you've seen the reviews but I bet not many have messed around with it. I will take challenge and not only install, but upgrade my current Windows XP virtual machine running in Parallels to Ultimate Vista.
Basically I am doing this because I do not want to install Vista on a clean image and have to reinstall all the software that would require re-configuration. What I have on my VM that I hope does not break in Vista is the following:
- Live Writer
- Visual Studio 2005
- Office 2004
- Visual Source Safe
Not to bad huh? I will keep posting my progress made when moving to the new OS by Microsoft.
As of now, I have just upgraded to the latest Parallels version which should let me upgrade to Vista...launch the installer and TADA:
One click after I get my first obstacle:
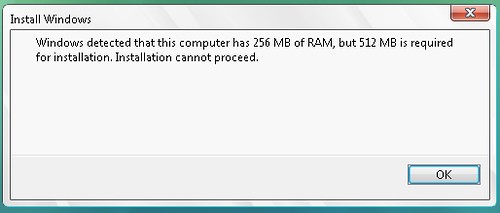
Turning off VM and increasing memory...BBL
Today Microsoft released the final version of Virtual PC 2007. You can download it here. This version fully supports Vista, both as a Host and a Guest, supports AMD and Intel hardware virtualization, and also supports 64–bit Host operating systems.
You can get some more information at the Virtual PC Guy’s WebLog, or directly on the VPC 2007 homepage.
A recent article by Jason Pontin on the Ney York Times began with exactly these words. It went on like this:
... Software failures cost $59.5 billion a year, the National Institute of Standards and Technology concluded in a 2002 study, and fully 25 percent of commercial software projects are abandoned before completion. Of projects that are finished, 75 percent ship late or over budget.
The reasons aren’t hard to divine. Programmers don’t know what a computer user wants because they spend their days interacting with machines. They hunch over keyboards, pecking out individual lines of code in esoteric programming languages, like medieval monks laboring over illustrated manuscripts.
Worse, programs today contain millions of lines of code, and programmers are fallible like all other humans: there are, on average, 100 to 150 bugs per 1,000 lines of code, according to a 1994 study by the Software Engineering Institute at Carnegie Mellon University. No wonder so much software is so bad: programmers are drowning in ignorance, complexity and error.” ...
Doesn't the above paragraph look like the perfect reason why an automated migration of a valuable application makes sense? When you are doing an automatic migration you do not have to guess the intentions of the users. You have the perfect specification. You have a working application! Then you might ask, if it is working why should you even touch it in the first place? And we are going back to the reasons to migrate. Typically an application becomes a candidate for a migration if it continues to support the business but need to evolve and it is written in a technology/platform that does not provide the best advantages to the current business scenario. When an application meets these characteristics one of the common decisions is to throw it a away and re-build it! Here is when we again enter in the cycle where most projects go down an unmanageable spiral of over time and over budget mainly because of the isses in translating business requirements into working code. An alternative is the automated migration. Take the best possible specification (the app itself), use the computer to upgrade it to a more modern environment (automatic migration) and take advantage of the latest techniques that software development tools can provide (.NET). Why start from scratch when all you need is to continue to evolve a working app on a modern set of technologies? VB6 application can be moved .NET, it is possible to extend their life, recover all the embedded knowledge and continue to extract value from them for years to come.
If programming is so hard as the New York Times implies, why shouldn't we use techniques to reduce the amount of required programming? Automatic migration is one of those techniques. The article goes on illustrating another potential solution: Intentional Programming. The idea is to capture the intention of the users and translate them into usable programs. Again, more support for my thesis, why not use a working application as the source of intentions?
In order to get the most from a time reporting system, several requirements should be met. Historical data that is accumulated in the system will be more accurate and meaningful depending on the way team members report their hours.
Periodicity is very important. Time reports are usually more accurate when team members update their hours daily. If reporting is done weekly, team members will hardly remember how much time they spent on each task at the beginning of the week.
Insist that team members report their hours accurately. Sometimes people don’t work exactly 8 hours a day, so when time reports are “flat” (i.e. 8 hours every day), you may be looking at a symptom of inaccurate reporting.
It is also important to break down the tasks in meaningful sub-tasks, so team members won’t be confused when reporting their hours. If possible, include a description of the tasks; this description will serve as a future reference for post-mortem analysis and historical data retrieval.
Finally, it is not recommendable to use reported hours as a criteria to reward team members. Doing so may introduce more biases in the reports and may cause a negative team response.
Establishing a time reporting system within an organization can be a very challenging task, but it presents important advantages once the system is in place. Let’s face some hard facts about time reporting:
-
Time reporting is necessary: if you don’t know how much time the team is spending on each task, you’ll hardly know if the original effort estimates for the tasks were correct. Also, time reporting allows you to keep historical data that will be helpful in estimating future projects and optimizing your processes.
-
Time reporting is overhead: of course time reporting is not part of the main tasks that your team members are supposed to execute. Because of this, your time reporting system must be fast, friendly and easy to use. If a team member spends more than five minutes reporting his/her hours, then something’s wrong with the system. Also, if a project manager or team leader has to spend hours chasing team members that haven’t reported their hours on time, then there is definitely a problem.
-
Time reporting is cultural: nobody really likes time reporting when it is first introduced. If there is no plan to communicate the advantages of time reporting to team members, they will probably be reluctant to report their hours in a periodic and timely manner. Basically, you have to sell everybody the idea that time reporting is important and key to the project’s success. Organizations that have succeeded at creating a time reporting culture now possess extensive historical data and knowledge about their own processes.
By taking at look at Web Pages, we may expect to discover that
some patterns of semantics are encoded using very few HTML sets of, let us say, “combinators”
(HTML parts); this may be due to the lack of abstraction capabilities which is
inherent to the HTML alone. We have compared this situation to the Noisy-Channel model in a previous post
where we presented some interesting figures and data illustrating the claim.
Let us continue our journey showing further instances of this phenomenon whose formal
analysis is crucial for intelligent refactoring tools as the kind we have been pursued to introduce by
means of this sequel of posts. In other words, let us know other forms of “HTML noise”. As a word of warning, we recall
that the data is the result of a particular muster of crawled pages by the way we explained before.
For this post, we are experimenting
with tables that are potentially used as page layouts or page structure. For
those kinds of tables, we want to study the table shape or page surface, no the specific content; we may think of that as a
way to filter potential candidates for further deeper semantic analysis. (We briefly
recall that our muster contains 819 pages and about 5000 table instances,
roughly speaking.).
The exercise is simple: we
postulate an intuitive definition for a table as surface and see how well it is
supported by our data in muster.
Let us try our shallow analysis
by classifying a table as a page layout candidate
if its container is the page body
tag, eventually followed by a chain of div
tags (assuming such div tags are intended to be organizers or formatters of the
table), it has at least two rows and at least 2 columns (two columns is the
most interesting case, we consider it as a base).
Such a pattern definition sounds
reasonable in appearance; however, we will see that its empirical support is
not as high as one may expect, at least in our muster.
We find 261 of such candidates;
they represent a 31% of all pages, which is a quite interesting amount; however
it is unexpectedly small because one may guess there should be at least one per
page. Among these 261, we have 83 where the table is hanging directly from the
body tag (32% of the candidates; 10% of the whole muster). As a matter of fact,
such 83 tables present irregular patterns, albeit often we find 2 columns (65%)
with a high variance. For instance, we may find a pattern of the form 6.2.2.2.2.2.2.2,
where we use our convention of showing a table of n rows as a sequence of n
numbers, each of one being the number of cols (in example 8 rows, the first of
them with 6 columns the rest having 2 columns). But even worst, we find the
irregular pattern 2.2.7.2.7.7.6.5.5.4.4.5.2.3.2.7.2.7.
And talking about irregularity, let us take a look at this interesting one: 19.2.7.4.6.2.2.2.2.2.2.2.2.2.2.5.7.2.2.2.2.4.4.2,
whatever it means.
With this simple analysis, we may
learn that, perhaps, some intuitive definitions occur not as frequent as we may
expect in our muster. Actually, and after seeing in detail some of the irregular
cases, a sound conclusion might be that we may need first to pre-classify some
parts of the page before using general patterns like the one we directly tried.
In other words, we see that some noise needs to be filtered out for such a kind
of pattern.
In a forthcoming post, we will continue
studying that kind of patterns and their support.
Last week, a developer from a company that is evaluating a trial version of the Visual Basic Upgrade Companion sent us an email, asking if they should use the Microsoft Visual Basic 6.0 Upgrade Assessment Tool and the Code Advisor. Perhaps someone else has a similar doubt, so I thought it may be a good idea to share our response here.
First of all, let's remember that we are talking about three separate --and different-- tools:
- Visual Basic Upgrade Companion (VBUC): this is ArtinSoft’s Visual Basic 6.0 to VB.NET/C# migration tool. Basically, you use this tool to convert your VB6 code to .NET.
- Microsoft Visual Basic 6.0 Upgrade Assessment Tool: this tool was written for Microsoft by ArtinSoft, and can be downloaded free of charge from http://www.microsoft.com/downloads/details.aspx?FamilyID=10c491a2-fc67-4509-bc10-60c5c039a272&DisplayLang=en. The purpose of this tool is to generate a detailed report of the characteristics of your VB6 code, giving you an idea of the size and complexity of the code from a migration standpoint. The tool itself does not make any modification of conversion of the source code.
- Code Advisor: this tool is also provided by Microsoft, free of charge, and can be downloaded from http://www.microsoft.com/downloads/details.aspx?familyid=a656371a-b5c0-4d40-b015-0caa02634fae&displaylang=en. The Code Advisor analyzes your VB6 source code and looks for particular migration issues within the code. Each issue is marked with a code comment that suggests how to modify the VB6 code to avoid the problem.
The purposes of the Microsoft Visual Basic 6.0 Upgrade Assessment Tool and the Code Advisor are different, so it is recommended that you use both of them. However, it is important to note that the Code Advisor was designed for users that plan to migrate with the Visual Basic Upgrade Wizard (the conversion tool that comes with Visual Studio .NET), and since VBUC has a greater migration coverage, some of the issues that will be flagged by the Code Advisor will be fixed automatically by VBUC. For a detailed discussion on those issues, please refer to my article “Visual Basic Upgrade Companion vs. Code Advisor”: http://www.artinsoft.com/VB-Upgrade-Companion-vs-CodeAdvisor.aspx
Yesterday, one of the attendees from the
Virtualization events asked this question which I though would be worthwhile to share:
For a simple .NET application like this, would we need different applications when running on 64 vs. 32 bit hosts?
Before answering, please allow me to elaborate more on where the question is going. Virtual Server has a COM API that allows it to be managed by applications and scripts. Virtual Server R2 SP1 Beta 2 (phew) comes in two flavors: 32-bit and 64-bit. The owner of the question wondered if you could manipulate a 64-bit instance of Virtual Server using a 32-bit application (or vice-versa).
Ok, now that the question is (hopefully) a bit clearer, the answer to the question is
no, you do not need to have a different version for accessing Virtual Server from an application regardless of its bit-architecture. Why? Virtual Server's COM API is accessed by an out-of-process COM library, which means that everything is done by means of RPC. When two applications are communicating with each other by means of RPC, the 1st commandment of 64-bit is
not broken (thou shall not run 32-bit and 64-bit code within the same process space).
Riddle me this: How many licenses of Windows Server Enterprise Edition would you need if you are planning on running 20 Virtual machines inside a server that has 2 processors? Very, easy, you would need only 5 licenses. Too tough? How about this one...what would be the price difference if you were running 50 machines running Windows Server 2003 on a virtualization server with 2 processors if you chose to run the host machine with Windows Server Enterprise Edition vs. Windows Server Datacenter Edition? Very easy...running Datacenter edition would be $25,580 cheaper.
It definitely is tempting to say that I can pull this info right off the top of my head, but that would be a big big lie. The secret lies in the sweet web application Microsoft has published. It is called the
Windows Server Virtualization Calculator, and without a doubt, it will clear a lot of doubts and will show you the best way to go (in terms of licensing) when consolidating your data center, enjoy!
Have you ever seen the Exit rows in an airplane? They longer leg space than coach, and after business or first, they are the best seats in the place. The bad news is that these seats are not reserved for anyone, or at least not in American Airlines. These seats are reserved for those travelers who have some kind of status such as Platinum or Gold. This means that if you do not have a status, you cannot choose them on-line (the seats will show up as unavailable), but fear not - I have found a workaround in some cases.
Say that you have no status at all in American Airlines, but you are traveling with a colleague or friend that does have this status. Before purchasing the ticket, you must tell your travel agent to place both tickets within the same record locator. The person with the high status will be able to select these exit rows for you and you will be able to fly a lot comfortable without having to have a high status.
Be warned that if 2 or more people are on the same American itinerary, and one of them selects an Upgrade to business, everyone in the itinerary will have a request to first. If they do not have enough upgrade stickers, the consequences can be quite bad - such as losing the exit row that was pre-selected and having to fly (if lucky) on the worst seat in the plane :S
During a migration project, the issues that your team will face may tend to become repetitive. Because of this, it is important that you have mechanisms that allow team members to share the knowledge that they have earned in the process of migrating the application. This way, you are not likely to have a team member struggling to fix a migration issue that someone else in the team already knows how to solve.
An ideal way of sharing team knowledge during the migration process is the creation of a Project Knowledge Base, where team members can post the solutions that they have applied to previous migration issues. With a good knowledge base, developers will be able to make searches and retrieve information that will help them fix the issues that they are facing, possibly increasing team productivity and reducing costs.
To be effective, your project knowledge base needs to have the following characteristics:
- Easy access: team members should easily retrieve information as well as add new items to the knowledge base.
- Search capability: of course, you don’t want team members navigating the knowledge base for hours to find a solution to a problem.
- Periodic backup: place the knowledge base on a server that is being backed up regularly. In a later project, the information stored may be useful again.
It is common to implement these knowledge bases using a Wiki engine. More information on Wiki can be obtained at http://www.wiki.org/wiki.cgi?WhatIsWiki.
Also, some examples of popular wiki sites are Wikipedia (http://www.wikipedia.org/) and Memory Alpha (http://memory-alpha.org/en/wiki/Portal:Main), this last one is a personal favorite :)
Ayer nos mudamos a las nuevas oficinas de Curridabat. A (casi) todo el mundo le queda más cerca de su casa y la verdad es que están muy lindas, por lo que reina la alegría. Poco importa que el edificio esté a medio construir. El nuevo lugar de almuerzo está genial y estamos por anotarnos en masa en un gimnasio con pileta y todo.El team room tiene muchas paredes y eso sacía mi apetito de post-its. Si me acuerdo, mañana traigo la cámara y empiezo a postear imágenes del lugar de trabajo.
En la retrospectiva del sprint #1 hubo un comentario de parte de un miembro del equipo que me pareció interesante: a pesar de nunca antes habíamos hecho Scrum, su sensación es que las reuniones eran un poco caóticas y que el ScrumMaster (i.e. yo) tenía que poner orden. Mi intención original era comenzar el proyecto siendo permisivo (timeboxing estirable, opiniones de miembros externos no moderadas, roles un poco difusos), pero me di cuenta que el truco está justamente en empezar siendo ortodoxo. Uno de los primeros puntos en los que decidí ponerme inflexible desde el comienzo mismo del sprint #2 es el timeboxing: las reuniones estaban comenzando tarde y muchas veces se extendían demasiado. Siendo que soy un tipo más visual que otra cosa, decidí comunicar la idea del timeboxing de la forma más explícita posible. Lo principal, claro está, fue el cambio en mi actitud, pero estos dos bichos me ayudaron bastante:
- El chanchito: una caja de cartón con un agujerito en su tapa. El que llega tarde a un daily meeting o a la retrospectiva paga según lo estipulado en una tabla que está pegada en la pared:
- 0'<t<5' : 200 colones (0,40$)
- 5'≤t<10': 500 colones (1$)
- 10'≤t": 1000 colones (2$)
- El sapo: una cajita simpaticona que tiene 4 posibles cronómetros - básicamente los únicos que usamos son el de 15' y 60' - a todo el mundo le parece simpática, pero además viene siendo muy efectiva
Nota: hasta el momento llevamos recaudados unos 7000 colones (14$) - la idea es usarlo para comprar snacks para picar durante las reuniones
Finalmente decidí darle un número al sprint abortado, por lo que el que acaba de terminar fue el #3 nomás. El review del viernes salió bastante bien...o por lo menos mucho mejor de lo que me lo esperaba. A diferencia del primer sprint review, esta vez hubo mucho demo y no tanta discusión filosófica. Creo que en ese sentido ayudó bastante el aclarar que íbamos a ser estrictos con el timeboxing y el simple de hecho de que ya habíamos tenido un review antes, que en mi opinión había salido bastante mal.
Unas horas antes del review MC y MR me dijeron que había que preparar una presentación (i.e. PPT, o al menos eso entendí yo) en las que se iba a introducir lo hecho en el sprint. Yo contesté que no era aconsejable invertir más de 1 hora en total en la preparación del review y que, además, el Product Owner era quien había elegido los user stories que iban a ser desarrollados, por lo que no valía la pena explicarle lo que él mismo ya conocía bien. La contra-respuesta fue que iban a asistir a la reunión
personas que poco sabían del proyecto (i.e. futuros miembros del equipo y un directivo de la empresa, así como LC). Mi contra-contra-respuesta, tal vez un poco dura, fue que no era responsabilidad del equipo subsanar el hecho de que no todos los stakeholders habían hecho sus deberes. La c-c-c-respuesta tuvo mucho sentido: "van a pensar que trabajamos mal". Y sigo en forma de diálogo:
- El review no es para quedar bien, sino para obtener feedback
- Pero de qué nos sirve el feedback de alguien que no entiende lo que ve
- Buen punto, pero no tapemos agujeros. Si hace falta que sepan y no saben, que se note
Sin embargo me quedó un sabor amargo después de esta charla...¿Quién tiene que poner al tanto a los stakeholders? ¿Y qué pasa si esos stakeholders están por ingresar al equipo?
Maybe I’m
wrong but after 8 year in web development, 4 asp classic year, 2 year
transition to .Net world and last year doing heavy development on asp.net 2.0 I
think that I may have a good opinion on the best resources online for the
asp.net development.
I was
thinking sometime ago about give the credit to the great work of
Mads Kristensen and his .NET SLAVE blog,
to me, the best blog around the blogsphere when talking about ASP.NET
development. But I’ve been kinda lazy and never did so, today I read a blog
post from HIM asking about some stuff , you should read here.
After
playing around with all free resources online to see coding techniques and
styles (forums, tutorial, blogs, Starter “piece of s***” kits, I easily can say
that Mads’ blog is the best asp.net blog around, why? Because if you see around
and read a lot of asp.net blogs an related technologies, forums, you can find
good code but NEVER believe me NEVER the complete solution, or not a quality solution,
and to make it even better Mads “KISS” approach just make his blog articles perfect.
I understand that people shouldn’t give away everything they know, that
everybody’s problem to decide to share or not.
Small,
concise, ready for deployment in must cases,
an the best of all, HE SHARES real solutions for real problems on real
scenarios, his code snippets are piece of gold when you have the enough
criteria to judge. I don’t want to sounds like a biased person, I don’t
know Mads personally but I bet you he is a great person why? Because persons
who SHARE KNOWLEDGE, - not just simple knowledge –I’m talking about real
knowledge, is great people. I invite you to read his blog everyday and if you
can donate when find something useful I encourage you to do so ( I should do
that to J) Read all the post
Mads wrote, I guarantee you that would be amazed to read all that valuable
asp.net an C# stuff.
I will make
a resource or blogs list that I read everyday that keeps me on track on latest
news, trends etc, related to an asp.net developer but now I just feel necessary
to give Mad something small back compare to his great knowledge.
As I said
Mads code snippets and opinion rocks, and here is my favorite ones.
Latest: http://madskristensen.dk/blog/Search+Engine+Positioner.aspx
Search Engine Positioner, I saw this yesterday
and now is used in our marketing department, very valuable tool for SEO
(search engine optimization) , Mads If you read this, this is my "wish a song", Proxy settings, to use 3rd party proxies, this
is very useful when doing SEO out of the US because Search engines give results
depending on your IP country so if you do search engine marketing for another country
rather that yours ( in my case Costa Rica) that would be very valuable).
Some other
favorites:
And many more, if you put together all the code Mads
provides you can build a great software library to a small general purpose web
shop.
Thanks for all, Mads keep sharing, keep rocking!
Visit the
.NET SLAVE BLOG now !